我有两颗强劲的“芯”:
RAGE Fury MAXX显卡
1999.10
(独家授权于《计算机应用文摘》)
ATI终于推出了被称作“Project
Aurora”的RAGE Fury MAXX显示卡,其高水平的性能、并行处理的技术又一次引起了业界的广泛关注。
Project Aurora
“ Aurora”(极光)的名称来自于传说中美国1986年的一种军用试验型侦察机,它能够在8倍音速、20万英尺高度飞行,使用脉冲式“爆炸”引擎。ATI从两年前开始了高度机密的计划“Project Aurora”,目标是开发出前所未有的高性能3D加速技术。今年3月,ATI才暗地透露了该计划的消息,半年后的10月7日,终于正式推出了“Aurora”的第一个成果――RAGE Fury MAXX显示卡。
RAGE Fury MAXX
ATI的这块显示卡装有2块并行工作于125MHz的RAGE 128 Pro 3D加速芯片和64MB工作于150MHz的显示内存,相当于2块32MB的RAGE Fury Pro的并联。

RAGE Fury MAXX的主要优点是其超强的渲染能力,因为有了4条渲染流水线,它的图素(texel,每层纹理上的单一像素点)填充率可以达到5亿图素/秒,显示内存带宽达4GB/秒左右,今后RAGE Fury MAXX的核心频率同单芯片的RAGE
Fury Pro显示卡一样提高到143MHz时(显示工作内存工作在155MHz),将达到5.72亿图素/秒的高速度。当然RAGE 128系列一贯的高32位渲染性能(相对16位渲染速度下降较少),也被RAGE
Fury MAXX继承了下来。
它的缺点主要是并未集成有T&L几何变换、光源照射硬件加速功能,因此仍不能同第4代的GPU如GeForce 256和Savage
2000等相提并论,而只能同TNT 2系列、Voodoo
3系列、Savage 4系列和G400系列等第3代产品一较高下。
并行处理技术比较
让多块芯片或显示卡并行工作,以提高性能的方法,由来已久,主要有SLI、PGC和ATI现在的Multiple
ASIC Technology等。
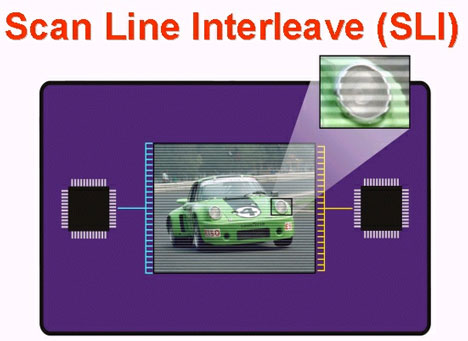
3dfx的Voodoo 2在1998年初采用的SLI(Scan Line Interleaving,扫描线交错)方式十分著名,实际上是让两套Voodoo
2分别处理图像的单数扫描行和奇数扫描行。将奇、偶行分开渲染的办法还算比较平衡,因为各自的总运算量比较接近。SLI连接的Voodoo 2一般需要3块卡(2块Voodoo 2,1块2D卡)和3个主板插槽。
Metabyte是一家著名的软、硬件公司,它开发的PGC(Parellel
Graphics Configuration,并行图形配置)技术,可以使用1块AGP显示卡和1块PCI同类型显示卡,由软件将它们联系到一起,并且将3D显示图像分为两部分,分别由两块显示卡处理。PGC的缺点是很少有公司愿意冒风险花资源为它优化驱动程序,因而执行效率普遍不够高;其次,两块显示卡的渲染量往往不平衡,因为图形的两半部分总是大相径庭的,这进一步拖慢了速度、降低了效率。

Bitboys的Glaze 3D芯片也具有2块、4块甚至8块芯片并行处理的功能,但我们还不清楚他们采用的不同于SLI和PGC的高效率方法具体是什么。
ATI在“Project Aurora”中开发的并行处理机制Multiple ASIC Technology(多重专用IC技术)力图避免SLI和PGC的缺点,ATI用独特的方式实现了这一目标,当然也为此申请了一系列的专利保护。

Multiple ASIC Technology的并行处理方法是让两块RAGE
128 Pro分别处理单数帧和奇数帧(帧是指视频回放中的每一幅完整的图像),即可称作“扫描帧交错”,有不少优点、也有少许缺点:由于高速渲染的3D图形相邻两幅图像区别一般很小,所以比SLI和PGC的运算量分配更平衡,在出现特别情况时,还可能灵活地打乱顺序进行渲染;因为两块3D芯片工作在不同的帧上,所以不存在在SLI和PGC的同一幅图像内的拼接问题;两块RAGE
128 Pro的三角形设置引擎各自处理自己的“工作帧”的三角形设置工作,互不干扰,这样就没有SLI和PGC处理同一幅图像时的重复计算三角形设置数据的问题。两块3D芯片各有32MB显示内存,首先是它们同时工作带来了加倍的显示内存带宽,尽管没有达到理论的极限值4.8GB/秒,只有4GB/秒;其次显示内存使用中除了Z-buffer必不可少外,帧缓存(frame buffer)可能可以省掉通常Double
Buffer功能(双重缓存,本来是为了防止图像在绘制过程中碎裂、不连续等问题,必须在后台渲染完毕一帧图像后再送到前台显示出来,因此必须保留两套帧缓存)的消耗,因为两块RAGE
128 Pro各有自己的一套帧缓存(一个在前台,当然另一个在后台);至于纹理缓存部分,因为两帧图像的纹理内容可能一样也可能略有不同,RAGE
Fury MAXX的两组纹理缓存分别设定的方式是比较灵活的,总之Multiple
ASIC Technology的显示内存配置比较灵活有效,尽管并未达到单芯片配64MB显示内存的效率,但可以达到32~64MB之间、接近于64MB的实际效果。
芯片性能横向比较
ATI的RAGE Fury MAXX同第3代(只有渲染阶段)的3D显示芯片相比较,5亿或5.72图素/秒的填充率,已经大大超过nVidia
TNT2 Ultra的3亿图素/秒和3dfx Voodoo 3 3500TV的3.66亿图素/秒,S3的Savage
4系列和Matrox的G400系列就更加不用说了。在传统的3D加速芯片中,只要Bitboys的Glaze 3D 1200(12亿图素/秒,2块并行处理就是24亿图素/秒)还没有出来,RAGE
Fury MAXX就是第3代产品3D速度上的冠军,另外图形质量也可以同最出色的G400系列相提并论。
同第4代集成T&L几何、光照加速的GPU们相比又如何呢?nVidia的GeForce 256达到9.6亿图素/秒,S3的Savage 2000系列有6~8亿图素/秒,3dfx一时还推不出来的“Napalm”(Voodoo 4)则传说有吓人的14.4亿图素/秒,至于ATI是否很快会有集成T&L功能的新一代3D芯片还不清楚,但Matro肯定藏了一些秘密武器还不愿公开。一句话,RAGE
Fury MAXX的速度同划时代的第4代产品相比就有些不足了。
综上所述, RAGE Fury MAXX将成为传统(仅仅渲染阶段)的3D加速卡中的佼佼者,如果不能成为性能最高的话。
从以上分析中,我们亦可以看出并行处理技术的优势和局限:考虑到多块或多套 3D芯片的成本增加,使用并行处理技术可以生产出在同一代产品中性能比较领先的设计方案,有时在渐变而不是飞跃的两代之间(如从第2代到第3代)也可能保持优势,但在革命性的进步面前(如从第3代到第4代)就显得有些力不从心(性价比较低)了。
附:ATI RAGE Fury MAXX 64MB性能一览
双ATI RAGE 128 Pro图形引擎
双三角形设置引擎
双纹理缓存
5亿图素/秒的像素填充率
4GB/秒的显示内存带宽
2组32MB显示内存,共64MB
32位真彩色、1920x1200分辨率的3D加速
1920x1200/32位的2D加速
完整的OpenGL(ICD驱动程序)、Direct 3D、DirectX加速
硬件全速、全屏DVD加速
AGP 4X(AGP 2X兼容)
2线性、3线性过滤
线条、边缘抗锯齿
纹理合成
纹理压缩
镜面光照
视点矫正的纹理贴图
Mip纹理贴图
突起贴图
雾化、纹理光照、视频纹理、反射、阴影、点光源、LOD(细节层次)偏置和纹理变形等
|