划时代的TNT3
1999.4
(独家授权于《计算机应用文摘》)
很快NVIDIA公司的Riva TNT2 3D加速芯片就要上市了,TNT2和3Dfx公司的Voodoo
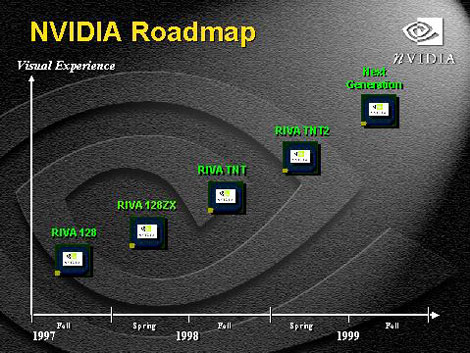
3系列在各种测试中正斗得如火如荼。竟然就在这个关键时刻,NVIDIA公布了它的3D芯片发展规划(如图1),其中包括大家还未有心理准备的TNT3!TNT3是Riva系列的下一代产品,继开发出TNT/TNT2的NV4计划之后的NV10计划就是针对TNT3的。TNT3的内部结构将比Pentium
III更复杂,因此内部不但集成了Riva系列一贯的2D/3D加速部分,而且还将集成有几何加速器――T&L。PC机的3D几何运算功能一向依赖于CPU的浮点能力,这一次NVIDIA竟然打算跳过作为PC心脏的CPU的限制,自行构筑一片3D显示的崭新天空,从此CPU的浮点性能将不再是3D图形系统的瓶颈了,这不能不说是一大创举,也是一大壮举。
什么是几何计算
3D图形的数据处理流程(见图2)可以分为几何计算和渲染两部分。
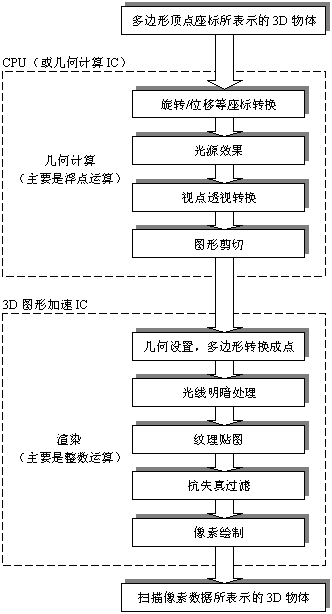
在几何计算部分,所有图形均是以多边形顶点坐标来表示的,这些顶点坐标通过一系列坐标转换后变成在空间中的实际物体坐标,经过光源照射的处理和透视转换,再进行图形的取舍后,最后将数据传送给渲染部分。由于空间中的坐标普遍用浮点数表示,所有这些操作都是以浮点的矩阵计算实现的,所以几何计算部分会用到大量的浮点运算操作。
在渲染部分的前端,空间多边形顶点坐标通过几何设置操作变换成线条数据,就是一一个个像素点表示的图形。这些图形经过明暗变化,贴上各种纹理图样,再经过抗失真过滤,最后真正成为显示器上看到的像素组成的图形。因为像素坐标与色彩值都是范围较小的整数值,所以除了几何设置是浮点操作外渲染部分基本上都是密集的整数运算操作。
怎样实现几何计算
几何计算过程,在传统的PC中是由CPU实现的。因为需要进行大量的浮点运算,CPU的浮点能力总是显得捉襟见肘,所以才有了我们现在熟悉的3DNow!(AMD的K6-2、K6-III和K7中)、SSE(Intel的Pentium
III中)和AltiVec(Motorola的PowerPC中)指令组,其实这几种指令组都是浮点SIMD(单指令多数据)指令,能够实现大量浮点数据的多路并行处理,所以常常又被称作3D指令组。
然而CPU毕竟是通用型计算器件,它不可能为3D图形处理作完全的优化,而且CPU在多媒体时代还必须兼顾很多其他工作,在3D应用中就是物理模型的建立、人工智能的实现、角色行为的模拟和游戏的发展进程等,如果利用专用几何加速器代替CPU,CPU无疑可以省出时间做更灵活、更有创造性的工作。因为几何计算是运算密集而且高度重复性的工作,所以更适合于用单独的、面向应用的硬件方式来实现,这就是为什么硬连线处理器比通用型CPU或DSP器件更适合作为专用几何加速器。以往,专用的几何加速器往往使用在“天价”的图形发生器和昂贵的工作站中,实际上是一块或几块专用芯片:最有名的要算3Dlabs公司的Glint
Gamma硬连线几何加速协处理器,很多高档专业3D显示卡都少不了它;Fujitsu公司的MB86242几何加速芯片则能同普通3D芯片一起实现很高的3D加速性能,即使在浮点性能较低的6x86MX
CPU上也不受影响;据称Videologic公司也在研制类似技术,很可能同PowerVR
Series3有关。
划时代的TNT3
由于以往的几何加速器是专用芯片或芯片组,销量较小,必然成本高、售价贵;若是生产一块含有几何加速功能的显示卡则必须在普通显示卡的基础上增加这些芯片,大大增加了成本。所以TNT3的优越性并不在于它使用了几何加速器,而在于TNT3将2D、3D、视频、几何加速这几部分都集成在同一片硅片上。按照集成电路的经济学,随着技术的进步,只要是单硅片电路,成本都必然可以降到几乎同一水平上来,这就是说当TNT3上市时,我们将拥有同现在的TNT价格相近的TNT3,而它不需要CPU的浮点能力来进行几何加速。
在TNT3的研制计划NV10中开发的几何加速技术,NVIDIA称作T&L(transform
and lighting,变换与光照),TNT3是业界首片集成了几何加速器的单片2D/3D加速芯片,它也是首次针对主流3D图形市场的此类产品。通过同最新的标准API的联合与兼容,TNT3将在1999年的PC图形市场上提供首屈一指的3D加速性能。“T&L这一崭新的图形技术将是迈向交互式的‘玩具总动员’或‘侏罗纪公园’的第一步。”NVIDIA的首席技术专家David
Krik(大卫·柯克)这么说。TNT3集成的几何加速器将使CPU空出大量的时钟周期以改进3D软件和游戏的特性,其中的好处是双方面的:既可以使虚拟的空间的静态外观更真实,又能使它的各种动态变化更真实。TNT3的T&L技术为3D图形技术打开了一片崭新的天空,将使便宜而且高质量的3D图形迅速进入主流PC平台。新年伊始我就曾将专用几何加速器列为3D图形系统的发展方向之一,没想到现在它会这么快而且彻底地进入业界的发展日程之内。
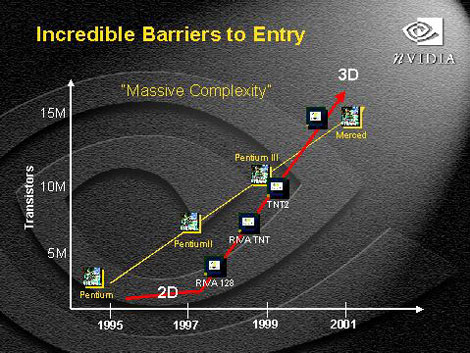
TNT3的特性现在公布的仍不多,但我们现在已经知道TNT3最大可以支持64MB显示内存。而且(图3中)我们可以看到它内部集成的晶体管数目与Intel的下一代CPU
Merced不相上下,约有1500万,这样复杂的显示芯片真是史无前例,同时从NVIDIA一贯的以复杂结构换取高速度的传统,我们也可以推断出TNT3应当是由一系列超级并行结构组成,加上不会低的内部时钟频率,总体速度必定惊人。至于生产工艺,TNT3很可能开始时会沿用现在的0.25微米工艺,到一定时候再转向0.18微米。

实力的较量
尽管有了划时代的集成T&L功能和Merced般的复杂程度,TNT3也还是不能自称“高手寂寞”,其他公司的主力产品中亦不乏有能力问鼎3D王座的“猛将”。
3Dfx公司是当今的3D霸主,但与NVIDIA之间的市场争夺战并未占得上风,Voodoo
3 2000/3000/3500系列与TNT2水平相当,还缺少了32位渲染能力,所以3Dfx真正的实力体现在下一代超级芯片上:每秒9亿以上的像素填充率,64MB以上显存,每周期4重纹理贴图,全速32位渲染――新3Dfx一定会是TNT3的劲敌。而去年就有所耳闻的Bitboys公司的Glaze3D芯片具有8亿像素/秒的填充率,还可以SLI连接,一旦面世实在是威风八面,对TNT3威胁不小。Intel的i752芯片则只能挑战TNT2,但到年底也该有新动作了吧?ATI的Rage
128Z和Matrox的G400MAX都是升级版芯片,分别比原版本的Rage 128和G400约有30%的性能提升,看来也是只能威胁到TNT2,要同TNT3较量还得再等一代产品。倒是NEC/Videologic合作的PowerVR
Series3系列将是首先使用0.18微米工艺的显示芯片,年底前上市时凭借独特的工作方式和较低的成本,可能会有同TNT3较量的实力。另外,S3公司继Savage4之后的产品应该是0.18微米的超级制作,价钱也该较低,按S3的速度年底前应该可以推出向TNT3挑战了。
还要等多久
从NVIDIA的3D芯片发展规划中我们可以看到,TNT3将会在年底以前出现,如果早到第4季度初投产也是有可能的。
在1998年等待Riva TNT的漫长时间里,我们看着它渐渐成形,一步步登上2D/3D加速芯片的王位,今年NVIDIA又是早早地吊起了我们的好奇心。尽管还要很久,但是等候一款革命性的产品并期待它的成功还是很有意义的。何况到时也许我们已经存满了升级的钱袋,可以拥抱属于新世纪的TNT3了呢?
参考资料来源:http://www.nvidia.com